AI全栈竞逐:六大生态的"引力井"格局
2/11/2026, 11:45:17 AM
摘要
当前的AI竞赛,已经不能停留在"谁的模型跑分高"这个层面讨论问题。现实远比这复杂——这场竞争的本质早已不是模型之间的比拼,而是演变成了"算力+模型+入口+应用"的全栈生态系统战争。谁能打通从底层硬件到上层应用的整个闭环,谁才有资格留在牌桌上。
截至2026年2月,全球范围内已经形成了六个相对独立、各自具备强大引力场的核心AI生态系统,外加若干围绕它们运转的关键"卫星"。它们如同六个"引力井",各自吸引着开发者、资金和用户——但也意味着同一种底层能力在不同生态中被反复建设、平行投入。理解这张高度分散的...
全文
当前的AI竞赛,已经不能停留在"谁的模型跑分高"这个层面讨论问题。现实远比这复杂——这场竞争的本质早已不是模型之间的比拼,而是演变成了"算力+模型+入口+应用"的全栈生态系统战争。谁能打通从底层硬件到上层应用的整个闭环,谁才有资格留在牌桌上。
截至2026年2月,全球范围内已经形成了六个相对独立、各自具备强大引力场的核心AI生态系统,外加若干围绕它们运转的关键"卫星"。它们如同六个"引力井",各自吸引着开发者、资金和用户——但也意味着同一种底层能力在不同生态中被反复建设、平行投入。理解这张高度分散的版图,是判断AI投资周期中哪些Capex最终会沉淀为基础设施、哪些会变成沉没成本的起点。
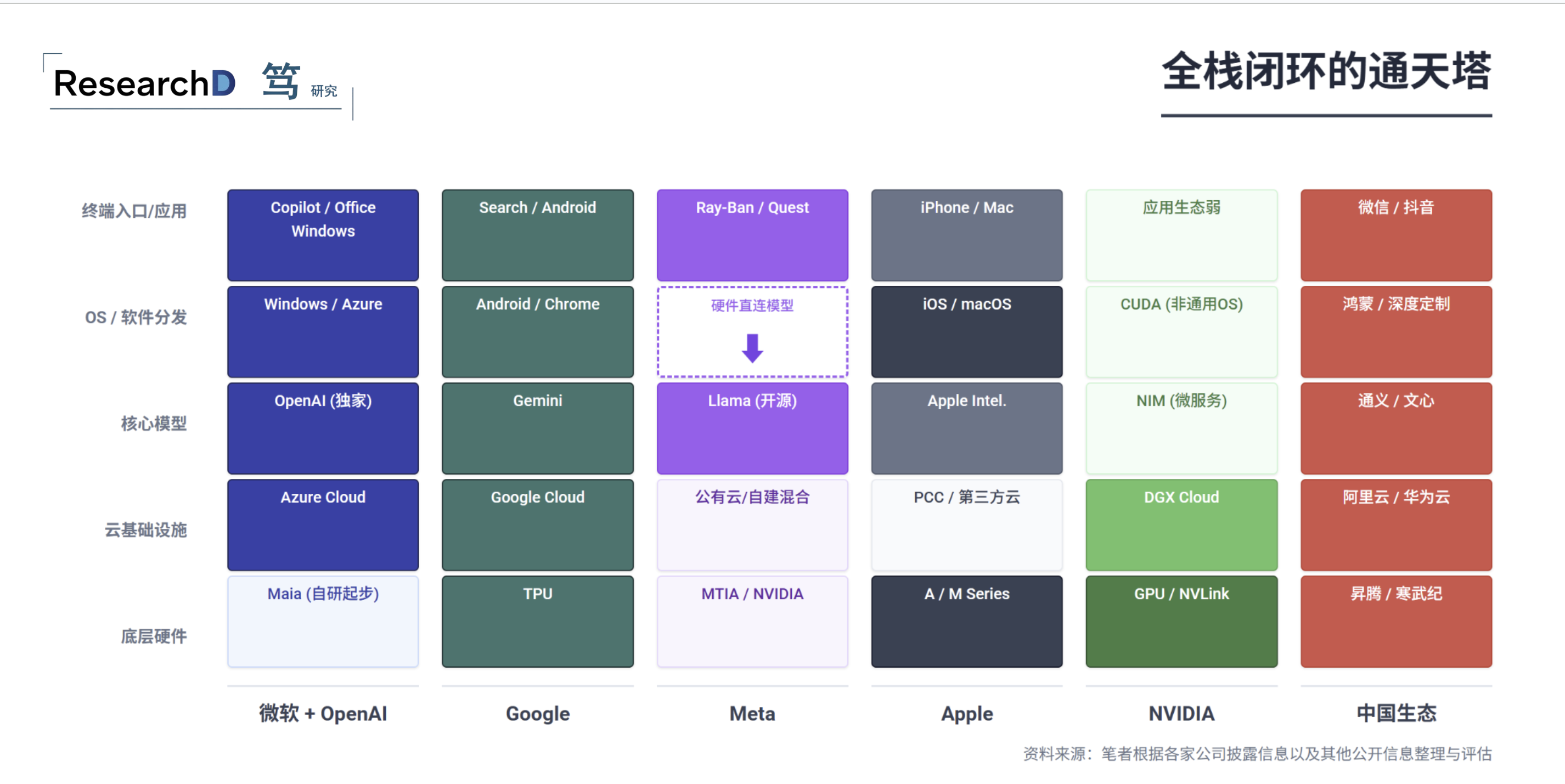
微软+OpenAI:"新Wintel"联盟
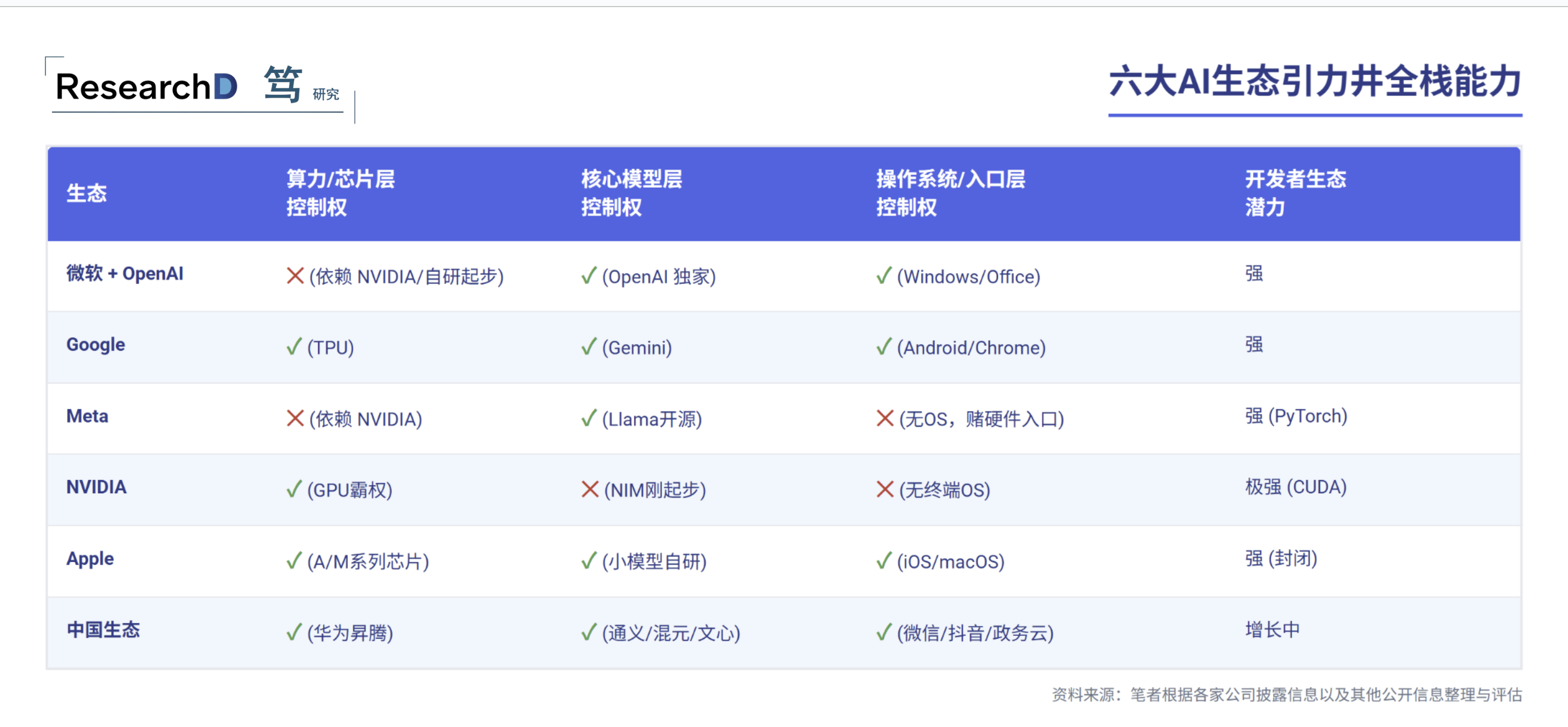
微软与OpenAI的组合是目前B端和生产力领域最强大的AI闭环,逻辑类似PC时代的Windows+Intel。OpenAI提供最强闭源模型(GPT系列/o1),Azure云服务通过独家合作锁定了OpenAI的算力输出,Copilot则深度嵌入Windows、Office 365和GitHub。全球500强企业几乎都在用Office体系,这使得Copilot成了落地门槛最低的企业级AI应用。
从最新财报看,Azure(含AI服务)在2025年Q4同比增长约39%,其中AI相关贡献了超过一半的增量。微软2025自然年广义Capex(含融资租赁)约1180亿美元,下半年支出从H1的456亿美元急升至H2的724亿美元,环比增长59%,反映了AI基础设施的集中上量。根据管理层口径及市场预期,2026年粗估将达1550至1750亿美元。
微软优先构建的是大规模推理基础设施,这种路径近期风险更低,但如果竞争对手在模型层取得决定性突破,或者模型开发商绕开现有合作伙伴自建基础设施,长期存在被颠覆的脆弱性。
Google:原生全栈闭环
Google是全球唯一一家从芯片到终端都能自给自足的巨头。自研TPU芯片不仅为了省钱,更是为了在架构层面摆脱对NVIDIA的依赖;Gemini系列是原生多模态模型;Android+Chrome+Google Search+YouTube构成了覆盖数十亿用户的入口矩阵。
Google Cloud在2025年Q4交出了一份极具说服力的成绩单:收入同比暴增48%至177亿美元,远超分析师Consensus的162亿美元,增速也从Q3的34%大幅加速。更重要的是利润——Q4运营利润达53亿美元,是去年同期21亿美元的2.5倍,远超Consensus的37亿美元。Google Cloud的backlog同比翻倍、环比增长55%,到2025年Q4末达到2400亿美元。这些数字意味着:在所有Hyperscaler中,Google Cloud的增量Capex-to-Revenue转化路径可见度是最高的。
Alphabet 2025年全年Capex约900至915亿美元,2026年指引1750至1850亿美元——几乎翻倍。按用途拆分,约60%投向服务器(含AI加速卡/TPU),约40%投向数据中心及网络等长周期资产。这个指引远超华尔街此前约1195亿美元的Consensus,将近高出50%。市场对此的反应是"又兴奋又紧张"——兴奋在于Cloud的增速证明了需求,紧张在于这么大的Capex,折旧黑洞在后面等着。
Meta:AI时代的"Android"
Meta的策略非常简单粗暴:"如果我不能拥有操作系统,那我就把模型变成免费的公用设施。"通过开源Llama系列,Meta事实上在推动大模型的”大宗商品化"——几乎所有非巨头公司的AI应用、学术研究都基于Llama微调,形成了庞大的PyTorch/Llama开发者生态 。只要Llama是行业标准的开源基座,开发者就会围绕Meta的技术栈优化,防止OpenAI一家独大。
Meta的差异化在于它正在布局硬件入口。据Bloomberg 2026年1月报道,Meta和EssilorLuxottica正在讨论将Ray-Ban智能眼镜的年产能翻倍至2000万副,甚至在需求持续的情况下冲击3000万副。由于美国本土需求过旺,还被迫推迟了Ray-Ban Display眼镜在欧洲和部分亚洲市场的上市进度。这意味着Meta正在用一条"开源模型+可穿戴硬件"的路径,试图在不控制操作系统的情况下建立自己的终端入口。但这很可能成为Meta的致命短板:坐拥34.8亿月活的分发优势,却不控制操作系统——不像微软、Apple和Google,Meta的一切都跑在别人的平台上,在AI工具的呈现方式上天然受限。Ray-Ban眼镜能否成为一个足够大的独立入口来弥补这个缺陷,目前仍是一个未经验证的赌注。
财务层面,Meta 2026年Capex指引为1150至1350亿美元,中值约1250亿美元,两年内基础设施支出增长约3.2倍,是Mag 7中增速最激进的公司之一。但其2025年自由现金流已从521亿降至436亿美元(降幅16%),Q4单季融资299亿美元长期债务,回购暂停至零。如果2026年Capex达到中值,即使经营现金流增长20%,FCF将接近零甚至转负。Meta的AI投资回报路径与其他巨头截然不同——没有直接的"云订阅/SaaS"入口,增量Capex到增量Revenue的路径要通过广告推荐效率的间接提升来兑现,这条路更长、损耗更大、可预测性更差。
NVIDIA:算力霸权,但"去N化"是一场慢仗
NVIDIA已不再只是卖芯片,它通过CUDA生态和NIM(NVIDIA Inference Microservices)试图介入软件分发层,成为软硬结合的AI平台。CUDA是目前AI开发的"物理基座",几乎所有生态(除Google TPU和华为昇腾)都建立在CUDA之上。
但"去N化"(De-NVIDIA-ization)的暗流正在加速——只是速度还没有市场此前想象中那么离谱。微软已经在Des Moines等数据中心部署第二代自研AI芯片Maia 200,采用台积电3nm工艺,针对自家模型栈(如GPT‑5.2)做了高度联调优化。据Forbes和The Meridiem在2026年1月的多篇文章,部分工程团队给出的测试显示,在特定推理负载下,Maia 200的性能功耗比可以接近、甚至略优于当前一代NVIDIA旗舰 。但这些数据高度依赖模型、编译器和工作负载设定,目前还不能简单外推为"全面超越"。
更重要的是,NVIDIA真正的护城河从来不在单点硬件参数,而在于CUDA生态的高黏性——迁移成本远不止"把模型从一块卡搬到另一块卡",而是整个工具链、运维体系和工程团队习惯的重构。整体来看,训练侧的CUDA粘性尤其高,自研芯片更可能是在推理侧蚕食份额。
行业渠道调研显示,自研加速器在Hyperscaler内部推理工作负载中的占比已经开始上升,NVIDIA在这块的份额从"几乎一统天下"滑落到"绝对主导但不再垄断"——大致从约90%降至约75%。但这更像是一场缓慢的"渗透战",而不是一夜之间的"切换":在训练侧,CUDA 生态短期内很难被撼动;在推理侧,即便自研芯片在某些负载的能效比更好,把真实生产环境从CUDA重构到自研堆栈,通常要以"年"为单位来衡量。现在就下结论说"去N化已经完成"是明显过于激进的。
因此,NVIDIA面临的不是"被替代"的风险,而是"被降级"的风险:从拥有定价权的"军火商",逐步滑向虽然不可或缺但定价权被大客户持续削弱的"公用事业"角色 。
Apple:端侧智能的"异类"
Apple在这场竞赛中的定位与众不同:不拼云端大参数,拼端侧体验和隐私保护。Apple Intelligence主要靠A/M系列芯片NPU在本地运行小模型,其护城河是20亿活跃iOS设备——唯一能打通个人数据(照片、短信、邮件)和AI能力的生态,且主要计算在本地完成,解决了隐私痛点。
Apple Intelligence的采纳呈现出"窄而深"的特征。据Morgan Stanley 2025年4月的AlphaWise调查,在已经拥有支持Apple Intelligence设备的美国用户中,近80%在过去六个月内下载并使用了AI功能,约42%表示AI对下一部iPhone"极其或非常重要",平均每月愿意为Apple Intelligence订阅付费约9.11美元。但后续数据显示,这个高使用率建立在一个很窄的分母上——目前全球iPhone装机量中仅约32%的设备支持Apple Intelligence。而从更广义的系统升级率来看,Apple Intelligence尚未成为拉动全量用户升级的杀手级功能:iOS 18的最终采纳率82%,略低于过去十年83%的均值;iOS 26发布后数周采纳率仅约15%,远慢于前代。换句话说,AI功能在"已到达"的用户中口碑不错,但还没有强到让更大范围的用户觉得"必须升级"。
Apple的Capex量级与其他Mag 7完全不在一个数量级。2025自然年约121亿美元,2026年市场Consensus仍维持在110至130亿美元——仅为四大云巨头的约十分之一。Apple的投资逻辑是一个与众不同的非对称赌注:将真金白银集中于研发而非基建,走“轻资产端侧路线”。这实质上是押注AI的终极价值将在设备端而非云端兑现——成功即颠覆整条云端AI资本链,把高资本密度、高折旧的算力基建变成"管线服务",而自己用20亿终端收走大部分溢价;失败则意味着在云端AI范式已经站稳的格局下,被边缘化为一个高端硬件供应商,继续赚稳定现金流,却可能丧失对下一代计算平台的话语权和估值想象力。
中国的"自主计算"生态
由于地缘政治和芯片制裁,中国正在形成一套尽可能摆脱美国技术栈约束的AI生态。核心是华为昇腾系列芯片+CANN软件框架+MindSpore深度学习平台,对标NVIDIA GPU+CUDA+PyTorch。这套体系正在快速上量:据Bloomberg报道,华为计划在2026年生产约60万颗旗舰级Ascend 910C芯片,较2025年大致翻倍;加上其他型号,昇腾产品线2026年总产量将达到约160万颗裸片。华为此前在2025年大部分时间里因美国制裁在出货方面遇到困难,但显然正在逐步克服这些制造瓶颈。
软件和模型生态的适配也在加速。华为官微披露的信息显示,已用约1000颗昇腾芯片联合浙江大学对DeepSeek R1进行安全方向的微调开发。DeepSeek最新模型一发布就同步适配了华为昇腾和CANN软件栈,这标志着中国头部模型厂商的优先级,正从"依赖NVIDIA CUDA"转向"确保国产加速器第一时间可用"。
在这套以昇腾+CANN为底座的中国引力井内部,又可以再拆出三个次级引力中心:阿里云担当类AWS/Azure的云+模型主轴,通义千问系列叠加PAI和OpenLake,承担了大部分民间大模型训练和推理的算力供给;腾讯则更像中国版微软轻量版,以混元挂接微信、企业微信、腾讯会议和广告,构成B端+社交双向引力井;字节跳动不是云,也不是芯片,但通过抖音和今日头条掌握了中国最大的多模态内容池,自研豆包模型主要用来反哺广告和内容分发,是一个以应用和流量为中心的AI重度使用者,而非通用AI基础设施提供方。
中国生态的逻辑不是"选择"独立,而是"必须"独立。阿里、腾讯、字节、百度等虽拥有通义千问、混元、豆包、文心一言等强模型和庞大应用场景,但在底层算力上仍处于从NVIDIA向国产加速器迁移的过渡期,距离"从芯片到云到应用完全打通"还有距离。不过,中国庞大的内需市场——智能制造、自动驾驶、政务云、文旅消费等——足以供养这套独立体系;类似北斗之于GPS,全球从技术上看只需要一个定位系统,但在战略上往往会演化出至少两个并行的基础设施 。
为什么没有第七个引力井?
一个合理的追问是:这张版图是不是画漏了人?全球云计算老大AWS、拥有数据库和ERP帝国的Oracle、手握X/Tesla/SpaceX数据管道的xAI、快速崛起的Anthropic,以及在数据治理层卡位的Databricks和Snowflake——它们难道不够格成为独立的引力井?
答案是:它们都很重要,但在"算力+模型+入口"三位一体的全栈框架下,没有一家具备独立成为第七个引力井的条件。
Amazon/AWS——最大的"缺席者"。作为全球云市场份额第一、2026年Capex指引高达约2000亿美元的巨头,AWS不在六大引力井之列并不是因为它不重要。但在本篇框架下,AWS更像是一台极其高效、却尚未完成"模型+入口"闭环的超级管道:没有ChatGPT级别的消费入口,没有Android/iOS级别的操作系统,自研Nova模型存在感远弱于GPT或Gemini,Bedrock的"模型商城"策略本质上是把定价权让渡给了第三方模型厂商。AWS到底是被低估的"隐形全栈",还是在向"高端IaaS管道"方向滑落,是一个需要独立展开的命题——后续报告会专门拆解。
Oracle——存量客户里的"堡垒"。Oracle依托全球最大的企业数据库和ERP装机基础,在OCI上叠加GenAI Service和第三方模型(Cohere、Grok等),本质上是把"云+数据库+GenAI"打包卖给现有企业客户。它在自己的存量客户群中构成了一个稳固的企业级AI闭环,但引力半径明显小一圈:无消费入口、无操作系统、开发者社区远弱于PyTorch/CUDA生态,在AI叙事权上也难以与四大Hyperscaler并列。
xAI(Grok)——有野心但缺闭环。xAI拥有独特的数据管道(X 平台的实时文本、Tesla 的视觉数据)和激进的算力扩张,Grok系列模型参数量已达数万亿级别。但xAI目前缺少通用云基础设施、操作系统和企业级SaaS——它更像是一个"有超级引擎但还没有底盘和轮子"的赛车,能否跑出独立生态取决于马斯克是否愿意、也是否有能力把X、Tesla和xAI整合成对外开放的平台,而非仅仅服务自家应用。
Anthropic——最强的"纯模型引力场",但没有自己的星系。Anthropic是当前除OpenAI之外最具话语权的闭源模型公司之一,Claude系列在推理、安全等维度拥有强品牌和高定价能力。但它的基础设施严重依赖 AWS——披露数据显示,Amazon对Anthropic的投资规模已达80亿美元,并换取了其在Trainium/Inferentia上的大规模工作负载承诺,Claude在企业侧的主战场也主要是通过Bedrock和第三方集成触达。Anthropic拥有的是局部很强的模型引力场,但缺少自己的云、自己的操作系统和自控入口,开发者主要通过AWS、Google Cloud或自行部署来使用Claude,而不是进入一个“Anthropic全栈生态“。在这个意义上,它更像是AWS/Azure的战略供应商,而不是一个完整的引力井。
Databricks/Snowflake——数据层的"必经之路"。这两家卡在一个极其关键的位置:所有企业想做私有化AI,都需要先把数据治理好。但数据平台的本质是"夹层"——无论谁赢了全栈生态战争,企业都需要数据治理,它们靠的是数据粘性而非算力壁垒或入口控制。它们是AI时代的"必需品",但不是"引力井"。
Perplexity——处在六大引力井之上的跨生态界面层。 觉得有帮助?分享给朋友,带来新用户可持续支持我们更新高质量内容。